MobileNetV2(Tensorflow)を触ってみた。

ブラウザ上からのMobileNetV2(Tensorflow)
による認識ラベル画像出力
・MobileNetV2とはモバイルアプリケーションなどのように制約された環境でも耐久して機能することに特化するように設計されたニューラルネットワークのことです。
・識別をMobileNetV2、検知をSSDとした物体検知(MobileNetV2)による認識ラベル付与済みの画像をブラウザ上に出力できることを目指します。
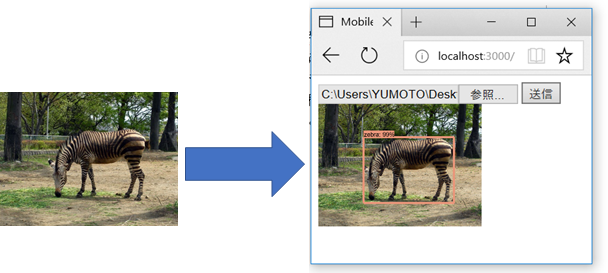
・環境はWindowsとします。ブラウザはMicrosoft edge 又はgoogle chromeとします。
MobileNetV2_SSD(Tensorflow版)の環境構築
・今回のMobileNetV2_SSDはGoogleが公開
しているTensorFlow Object Detection APIを使用しています。TensorFlow Object Detection APIはVGG16+SSD、MobileNet+SSDといった物体検知のネットワーク構造をモデル変更するだけで実装できるAPIで、2018年5月にMobileNetV2+SSDが公開されました。
・同時にマイクロソフトCoCoデータセットで訓練したトレーニングモデルも公開していいます。今回は、公開されているトレーニングモデルを使用した物体検知としています。
・TensorFlow Object Detection APIの環境構築
環境構築の流れは↓アドレスのブログと同じです。
https://qiita.com/x-lab/items/224e63565ecf1c3109cf
- Anacondaのインストール
https://www.anaconda.com/download/#windows
↑のアドレスよりAnacondaをダウンロードインストールします。
- TensorFlowのモデルをダウンロード
https://github.com/tensorflow/models
↑のアドレスをブラウザで開き右側にある[Clone or Download]→[DownloadZip]として[models-master.zip]をダウンロードします。
解凍した[models-master]を任意の場所に保存します。
- Protobufのダウンロード
https://github.com/google/protobuf/releases
↑のアドレスよりprotoc-3.4.0-win32.zipをダウンロードします。
展開したフォルダ内のフォルダbinに入っているファイルprotoc.exeを、先ほどのmodels-master内のフォルダresearchの中に移動します。
- PYTHONPATHの設定
環境変数の設定からPYTHONPATHを通します。
変数名:PYTHONPATH
変数値:~\models-master\research;~\models-master\research\slim
- Tensorflowのインストール
Cmdを起動して
pip install tensorflow
pip install Protobuf Pillow lxml
pip install Jupyter
pip install Matplotlib
を実行します。
- Protobufのコンパイル
コマンドプロンプト上でフォルダmodels-master内のフォルダresearchの中まで移動します。
cd ~~\AnacondaProjects\models-master\research
移動したら
protoc object_detection/protos/*.proto –python_out=.
↑のコマンドを打ち込みます。
コマンドの意味はobject_ditectionフォルダ内のprotosフォルダにある[.proto]ファイルをすべて[.py]ファイルに変換するという意味です。
Protosフォルダ内のファイルが全く変換されていなければ
↓のコマンドを打ち込みます。
protoc object_detection/protos/anchor_generator.proto –python_out=.
protoc object_detection/protos/argmax_matcher.proto –python_out=.
protoc object_detection/protos/bipartite_matcher.proto –python_out=.
protoc object_detection/protos/box_coder.proto –python_out=.
protoc object_detection/protos/box_predictor.proto –python_out=.
protoc object_detection/protos/eval.proto –python_out=.
protoc object_detection/protos/faster_rcnn.proto –python_out=.
protoc object_detection/protos/faster_rcnn_box_coder.proto –python_out=.
protoc object_detection/protos/grid_anchor_generator.proto –python_out=.
protoc object_detection/protos/hyperparams.proto –python_out=.
protoc object_detection/protos/image_resizer.proto –python_out=.
protoc object_detection/protos/input_reader.proto –python_out=.
protoc object_detection/protos/keypoint_box_coder.proto –python_out=.
protoc object_detection/protos/losses.proto –python_out=.
protoc object_detection/protos/matcher.proto –python_out=.
protoc object_detection/protos/mean_stddev_box_coder.proto –python_out=.
protoc object_detection/protos/model.proto –python_out=.
protoc object_detection/protos/multiscale_anchor_generator.proto –python_out=.
protoc object_detection/protos/optimizer.proto –python_out=.
protoc object_detection/protos/pipeline.proto –python_out=.
protoc object_detection/protos/post_processing.proto –python_out=.
protoc object_detection/protos/preprocessor.proto –python_out=.
protoc object_detection/protos/region_similarity_calculator.proto –python_out=.
protoc object_detection/protos/square_box_coder.proto –python_out=.
protoc object_detection/protos/ssd.proto –python_out=.
protoc object_detection/protos/ssd_anchor_generator.proto –python_out=.
protoc object_detection/protos/string_int_label_map.proto –python_out=.
protoc object_detection/protos/train.proto –python_out=.
Protosフォルダ内の[.proto]ファイルが[.py]ファイルに置き換わっているか確認し、置き換わるまでコマンドを打ち込みます。
- Anaconda navigator上での操作
- Anaconda navigatorの起動
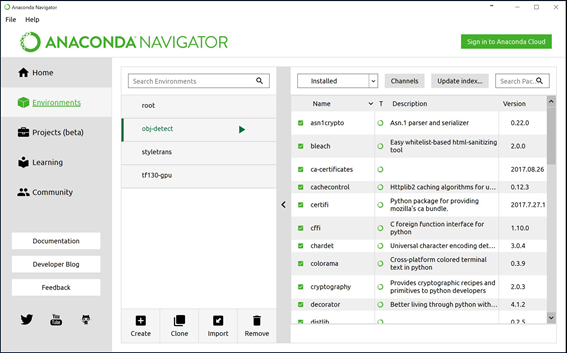
Anaconda navigatorを起動したら、画面左側のEnvironmentsをクリックします。上図のような画面になりますが、まだ何も作成していなければ、真ん中は空っぽだと思います。これからObject Detection APIの実行環境を構築していきます。
- 実行環境の構築
さきほどの画面の下部にある、Createをクリックします。実行環境の名前は任意に指定してください。Pythonのバージョンはデフォルトのままでよいのだと思います。私の場合は、名前はobj-detectとし、Pythonのバージョンは3.6としました。
実行環境が追加されたら、名前の右側にある三角ボタンをクリックしOpen Tarminalをクリックします。その後、自動的にコマンドプロンプトが起動します。
- モジュールのインストール
この実行環境にテンソルフロー、Pillow、jupyter、matplotlibをインストールします
pip install tensorflow
pip install Protobuf Pillow lxml
pip install Jupyter
pip install Matplotlib
↑をコマンドラインで実行します。
- 構築環境のテスト
Object ditectionは環境構築ができているか確認するためのテストプログラムがあるのでそれを実行する。
コマンドプロンプト上で
cd ~~\AnacondaProjects\models-master\research
python object_detection/builders/model_builder_test.py
を実行します。OKが表示されれば環境が構築できています。
ここでエラーが出た場合はobject ditectionの環境が構築できていないのでもう一度設定を確認してください。
- jupyterでの確認
Object ditection にはjupyter用のチュートリアルが準備されているのでjupyterで動作するか確認します。
まずカレントディレクトリをobject_ditectionに移動します。
cd ~~\AnacondaProjects\models-master\research\object_ditection
次にjupyterを起動します。
jupyter notebook
jupyter notebook が起動したらobject_detection_tutorial.ipynbをクリックします。
そして、下図のようにobject_detection_tutorial.ipynbが開いたら、Cellを押してRun Allをクリックします。
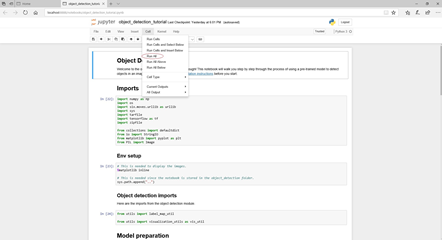
Jupyterで最後のシェルまでエラーなく実行できれば環境構築は終了です。
※warningが表示されても実行は進むので確認の場合は最後まで実行してください。
Object ditectionの環境構築は以上で終了です。
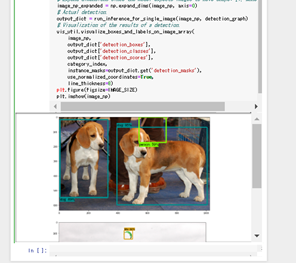
jupyter上での動作結果
- モデルの変更
初期設定のモデルはssd_mobileNetV1になっているのでMobileNetV2+SSDを導入するにあたりコードを下記のように変更してください
MODEL_NAME = ‘ssd_mobilenet_v1_coco_2017_11_17’
↓
MODEL_NAME = ‘ ssd_mobilenet_v2_coco_2018_03_29’
ブラウザ上で出力環境の構築
現状の環境はjupyterで画像を出力しているがjupyterはインターフェース固定でアップロード画面がありません。
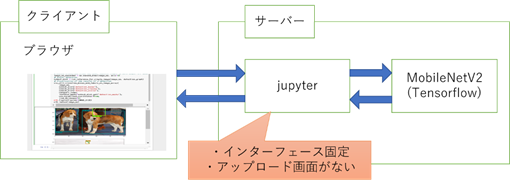
Node.jsを使用してアップロード画面が出るようにします。
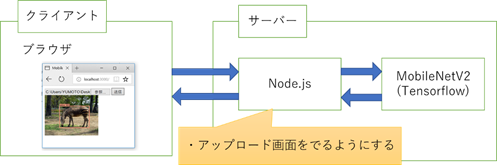
Node.jsの導入
- サーバーとしてjsが必要になるので、まずはNode.jsと、Node.jsのパッケージマネージャであるnpmをインストールします。Ubuntuなら以下のコマンドで導入できます。OSによっては「nodejs」が単に「node」のところもあります。
sudo apt-get install nodejs npm
- 次に適当なディレクトリ(フォルダ)を作り、作業ディレクトリとします。このディレクトリに入り、以下のコマンドを実行してnodejsプロジェクトとして初期化します。いくつかのことを尋ねられるが全部そのままEnterでいいです。
npm init
- js上のサーバサイドフレームワークであるExpressと、ファイルアップロードを補助するライブラリmulterを導入します。以下のコマンドで導入できます:
npm install express multer –save
- サーバとウェブページの作成
app.jsというファイルを作り、以下のコードを貼り付ける。詳しくはコード中のコメントを参照してください。
‘use strict’;
// child_process の execSync (Node上でシェルコマンドを実行する(同期的:処理が終わるまで次に行かない))
const execSync = require(‘child_process’).execSync;
const express = require(‘express’);
//fs = filesystem
const fs = require(‘fs’);
//multer nodeのアップロードを補助するモジュール
const multer = require(‘multer’);
//multer.diskStorage:アップロードの保管の設定
const storage = multer.diskStorage({
//destination:目的地
destination: function (req, file, cb) {
cb(null, ‘./’);
},
//filename:保管するときのファイル名
filename: function (req, file, cb) {
cb(null, ‘input-image.png’);
}
});
//storage:保管 保管の設定入れ込んだアップローダーの作成
const upload = multer({storage:storage});
const app = express();
// __dirname(現在の絶対パス)にあるファイルを静的に利用できるようにする。
app.use(express.static(__dirname));
// HTMLを表示
app.get(‘/’, (req, res) => res.sendFile(‘./index.html’));
// 画像アップロードをPOSTで受け付け
app.post(‘/’, upload.single(‘input-img’), function(req, res) {
console.log(`[done] Image upload`);
console.log(req.file);
// MobileNetV2を導入したディレクトリに移動し、
// MobileNetV2を実行する。するとpredictions.pngというファイルが出力されるので、
// それをウェブサーバのディレクトリまでコピーしてくる
//
console.log(‘MobileNetV2(Tensorflow) will do.’);
// execSync(コマンドライン形式でのコマンド指示)
execSync(`(cd ./models-master/research/object_detection && python mobileNetV2.py ${req.file.filename})`);
console.log(‘MobileNetV2(Tensorflow) done.’);
// httpレスポンスヘッダーのcontentTypeをapplication/jsonに変更している。
res.type(‘application/json’);
// path:predictions.pngに変更したJSON形式を文字列にいったん変換してレスとして送る
res.send(JSON.stringify({
“path
“: “predictions.png”
}));
// 応答プロセスの終了(これを送らないとブラウザ側がずっと待ち続ける。)
res.end();
});
// listenを開始する(待ち受け状態にする)
var server = app.listen(3000,’localhost’);
- 次にブラウザ側のインターフェイスとなるhtmlを用意する。Inde.htmlに以下のコードを貼り付けます。詳しくはコード中のコメントを参照してください。
<!DOCTYPE html>
<html lang=”ja”>
<head>
<meta charset=”UTF-8″>
<title>MobileNetV2(Tensorflow) Web</title>
<style>
.result-img {
max-width: 50vw;
}
</style>
</head>
<body>
<form method=”post” action=”./” enctype=”multipart/form-data”>
<input id=”input-file” type=”file” name=”input-img” accept=”image/*”>
<input id=”submit-button” type=”submit” value=”送信”>
</form>
<progress id=”progress-bar” style=”display: none”></progress>
<img class=”result-img”>
<script>
const submitBtn = document.querySelector(‘#submit-button’);
const progBar = document.querySelector(‘#progress-bar’);
const resultImg = document.querySelector(‘.result-img’);
// submitボタンがクリックされたら
submitBtn.onclick = (evt) => {
// ブラウザデフォルトの挙動をキャンセルする
evt.preventDefault();
// プログレスバーを表示する
progBar.style.display = ‘block’;
// HTTPリクエストのヘッダとボディを作成する
const headers = { ‘Accept’: ‘application/json’ };
const body = new FormData();
body.append(‘input-img’, document.querySelector(‘#input-file’).files[0]);
// Fetch APIを利用してサーバに画像を送り返答を待つ
// Fetch APIの詳しい利用方法は以下のURLを参照
// https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch
fetch(‘./’, {method: ‘POST’, headers, body})
.then(response => response.json())
.then((result) => {
// 帰ってきたJSONに画像のパスが含まれているので
// それをimg要素にセットする
const path = result.path;
// resultImgのソースをpath(predictions.png)+’?’+new Data()とする。
// (例)predictions.png?1530061678788
// 追加で画像を送信したときに表示画像を更新できるようにするため
var date_obj = new Date();
path_t = path +’?’+ date_obj.getTime();
resultImg.src = path_t;
// プログレスバーを非表示にする
progBar.style.display = ‘none’;
});
};
</script>
</body>
</html>
起動と動作確認
ここまでできたら、以下のコマンドでサーバを立ち上げる:
nodejs app.js
- サーバが立ち上がったらブラウザで http://localhost:3000/ にアクセスする
- あとはブラウザ上から画像を送信して、処理が終わるまでしばらく待てば認識ラベルがついた画像が表示されます。
![]()
株式会社アプリズムは
大手メーカー様の先端技術研究部署(Research and development、R&D)と連携し、
研究開発(システム開発)を行っており、お客様の企業価値向上の原動力として、
競争優位性を生み出す技術を開発します。
注力する領域として「IoT、AI/人工知能、機械学習」と定め、
アプリズムの強みを持つ技術を生かし、
さらに進化させることにより、研究開発の方向性を示すことで、
より良い暮らしと社会を実現していきます。
株式会社アプリズム
〒541-0053 大阪市中央区本町4-5-18 本町YSビル3F
